Abstract
At the core of sketching is the notion of abstraction, requiring the artist to convey a complex subject with a minimal representation.
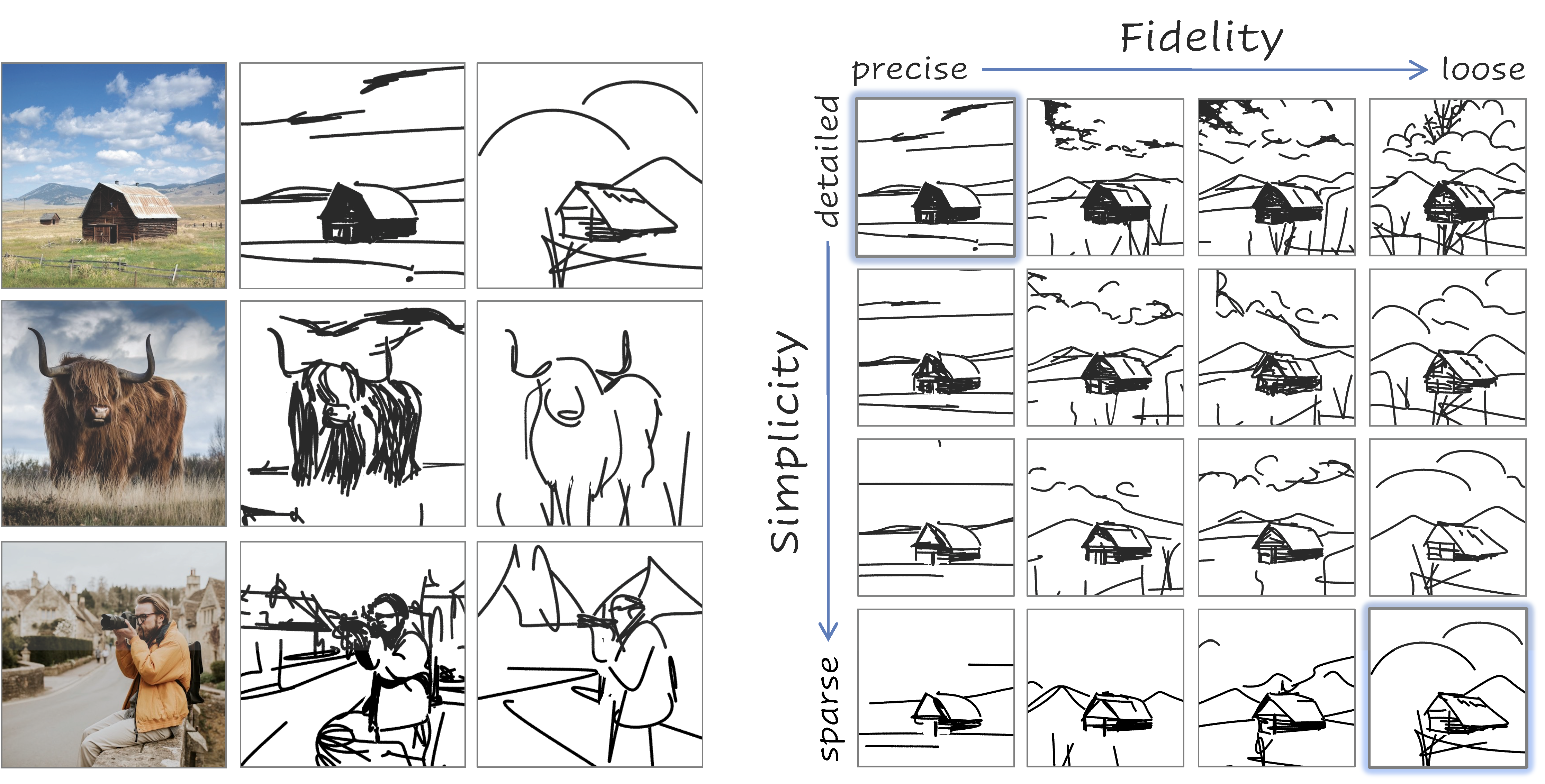
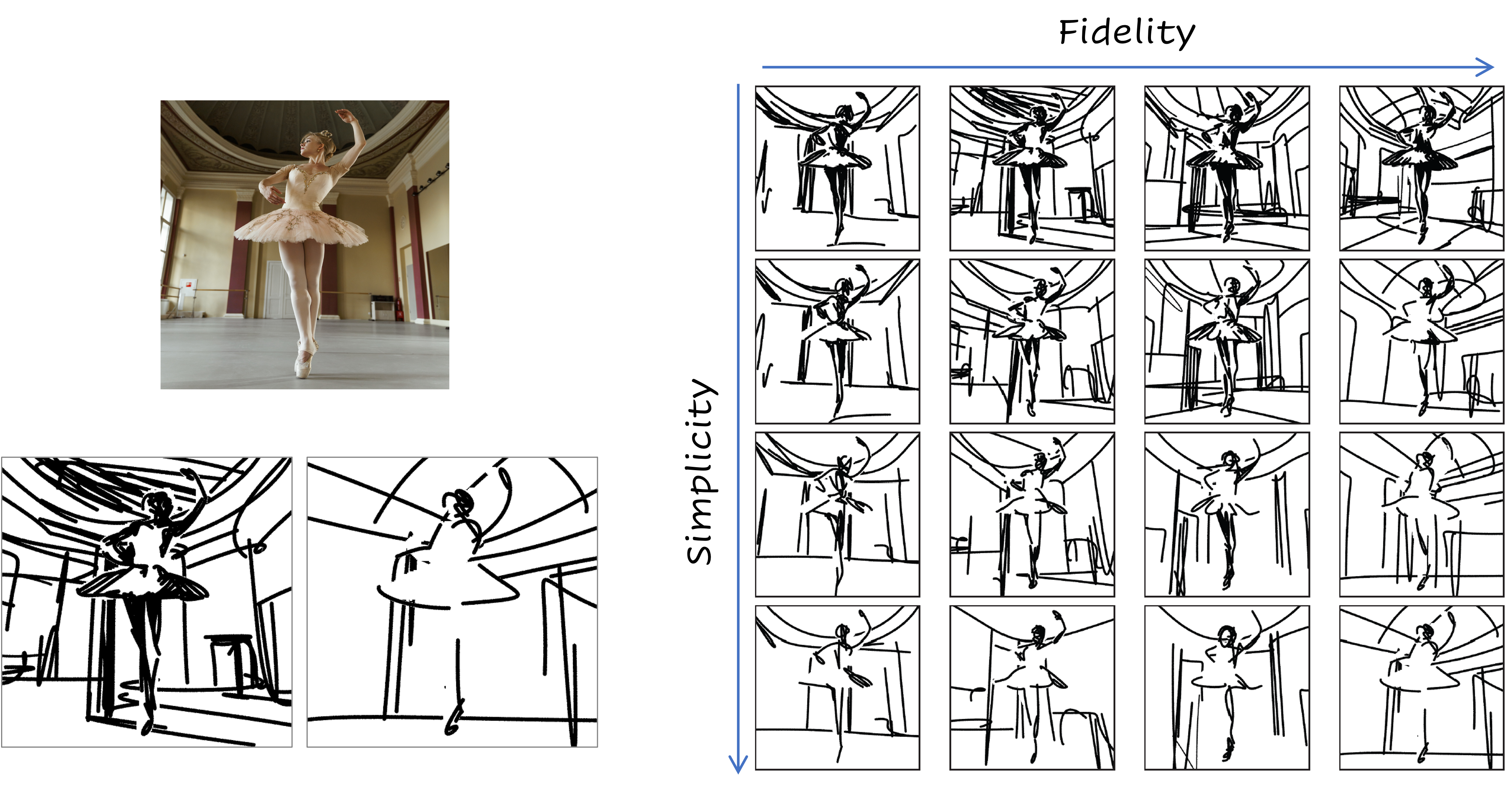
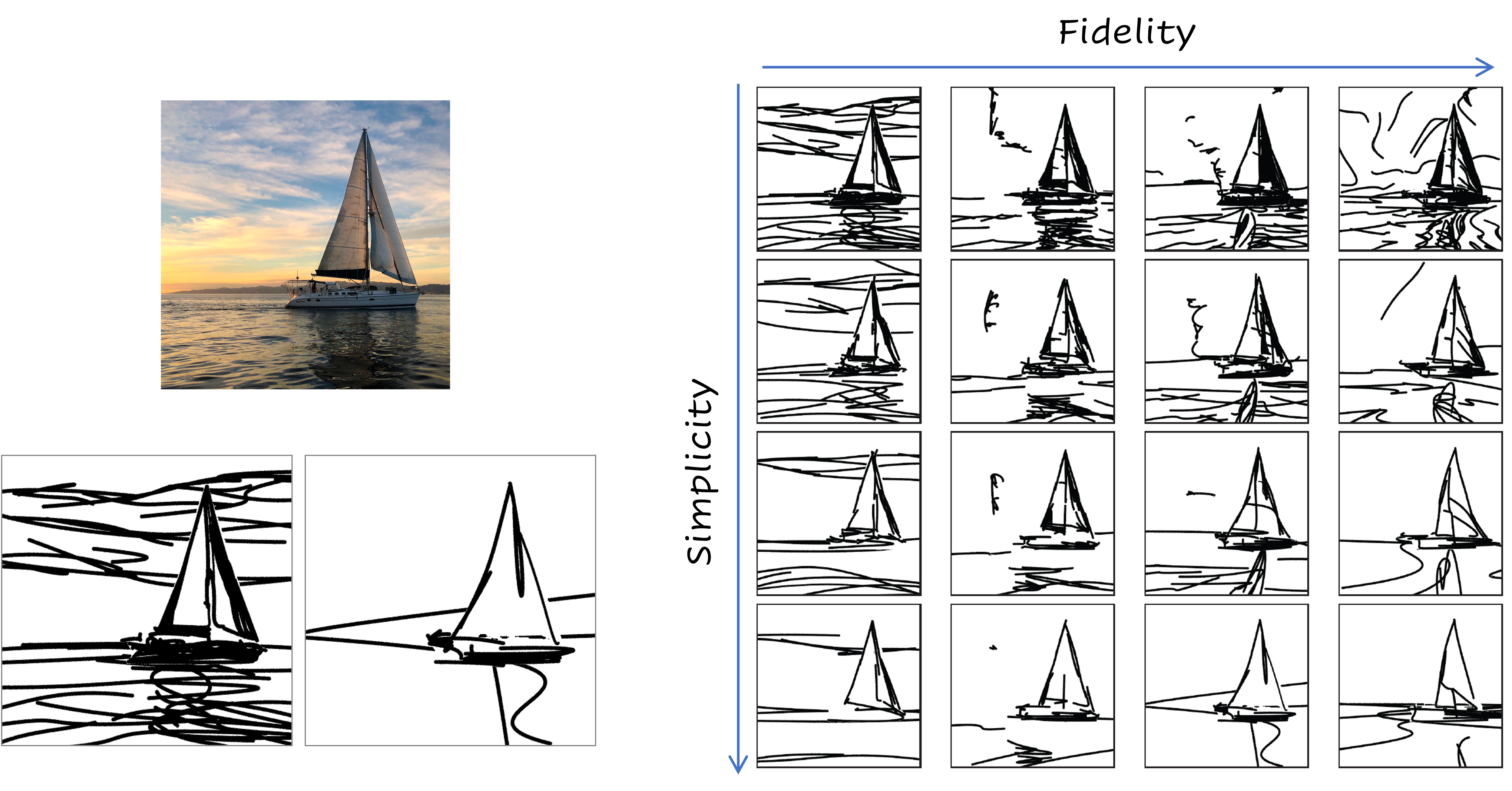
In this paper, we present a method for converting a given scene image into a sketch using different types and multiple levels of abstraction. We distinguish between two types of abstraction.
The first considers the fidelity of the sketch, varying its representation from a more precise portrayal of the input to a looser depiction.
The second is defined by the visual simplicity of the sketch, moving from a detailed depiction to a sparse sketch.
Using an explicit disentanglement into two abstraction axes --- and multiple levels for each one --- provides users additional control over selecting the desired sketch based on their personal goals and preferences.
To form a sketch at a given level of fidelity and simplification, we train two MLP networks.
The first network learns the desired placement of strokes, while the second network learns to gradually remove strokes from the sketch without harming its recognizability and semantics.
Our approach is able to generate sketches of complex scenes including those with complex backgrounds (\eg natural and urban settings) and subjects (\eg animals and people) while depicting gradual abstractions of the input scene in terms of fidelity and simplicity.



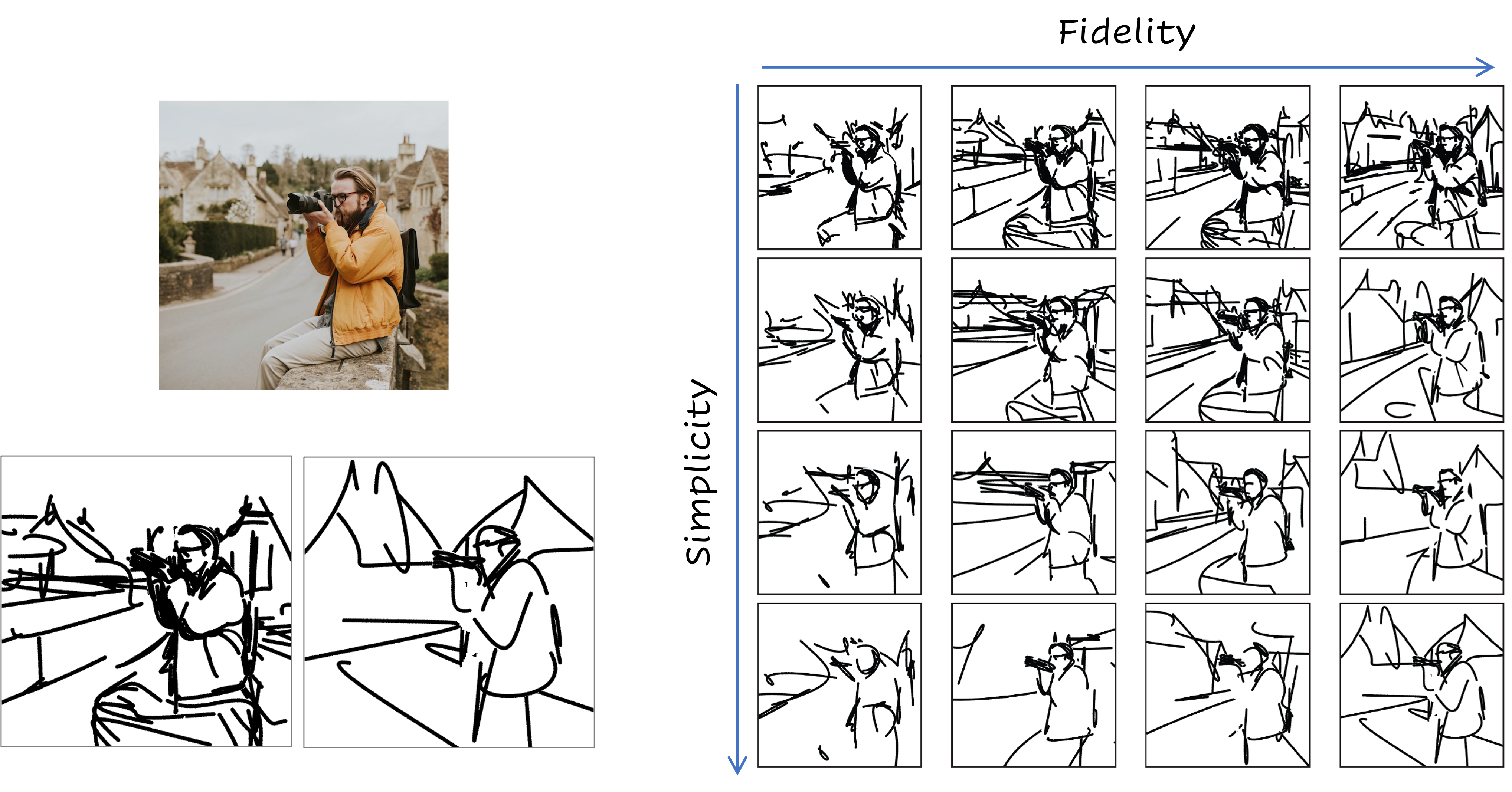

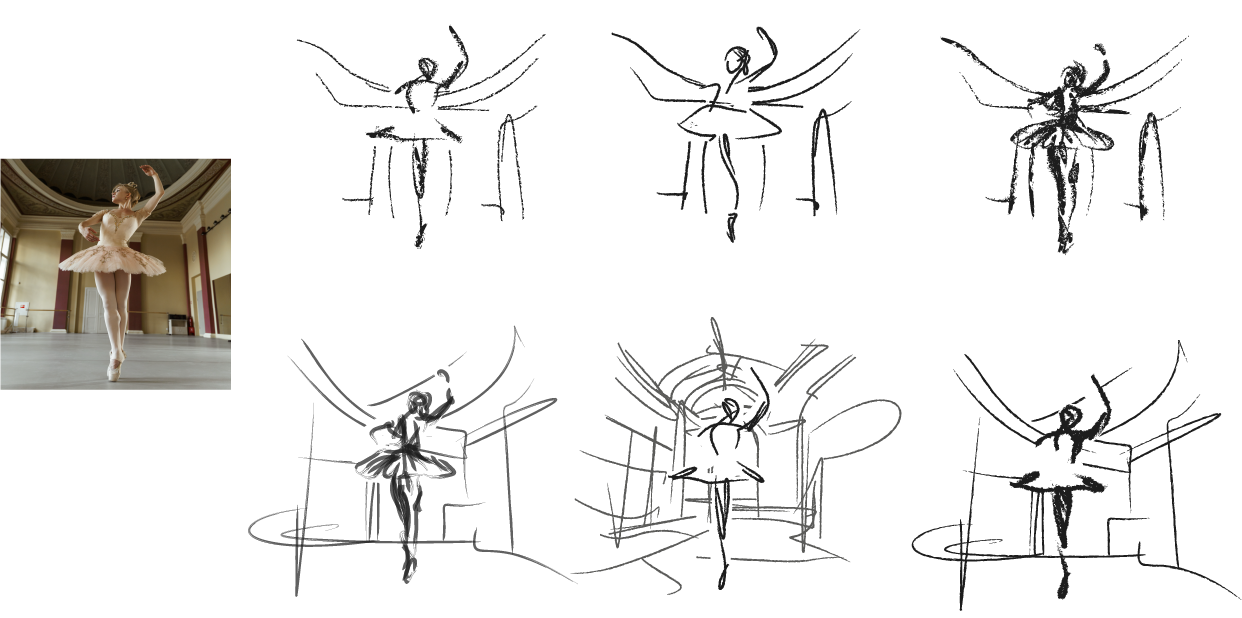
How does it work?
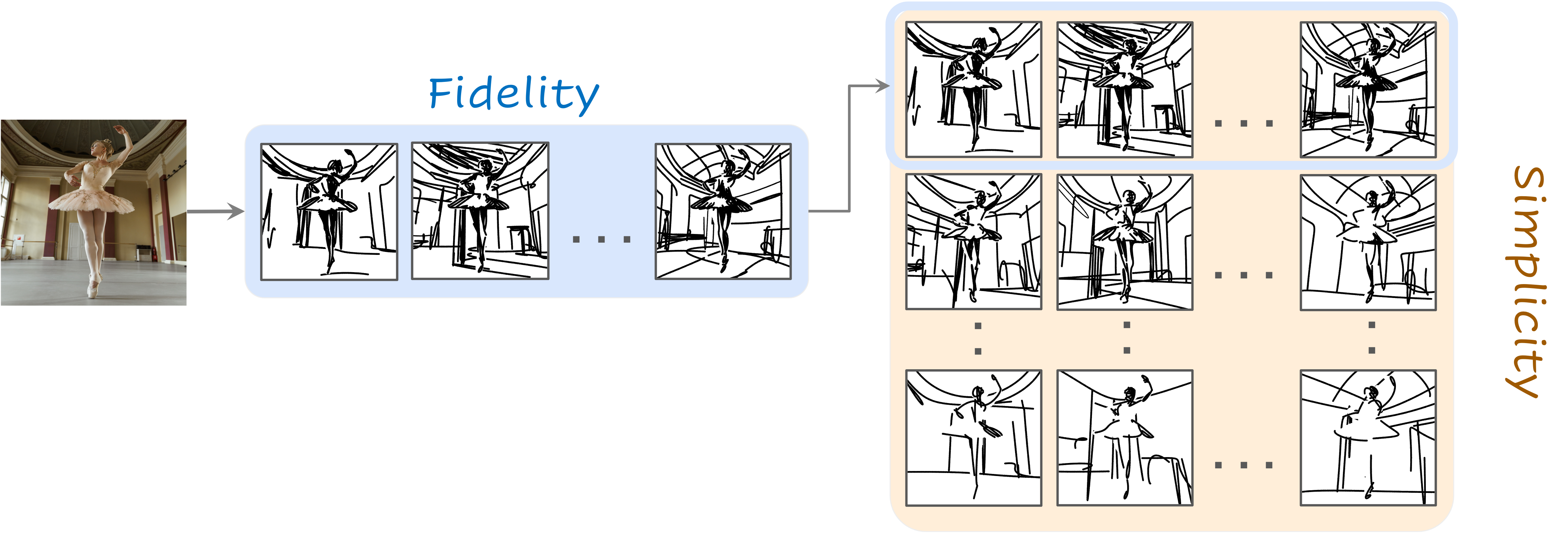
Given an input image I of a scene, our goal is to produce a set of corresponding sketches at different levels of abstraction in terms of both its fidelity and simplicity. We begin by producing a set of sketches at multiple levels of abstraction along the fidelity axis, with no simplification, thus forming the top row (highlighted in blue) in the abstractions matrix. Next, for each sketch at a given level of fidelity, we perform an iterative visual simplification (highlighted in orange) by learning how to best remove select strokes and adjust the locations of the remaining strokes. This process results in an abstraction matrix representing various abstractions of the complete scene.
We define a sketch as a set of n black strokes placed over a white background, and train a simple multilayer perceptron (MLP-loc) network to map an initial set of stroke parameters to their final locations forming a single sketch. The training process is done per image (e.g. withtout external dataset), and is guided by a pre-trained CLIP-ViT model, leveraging its powerful ability to capture the semantics and global context of the entire scene.
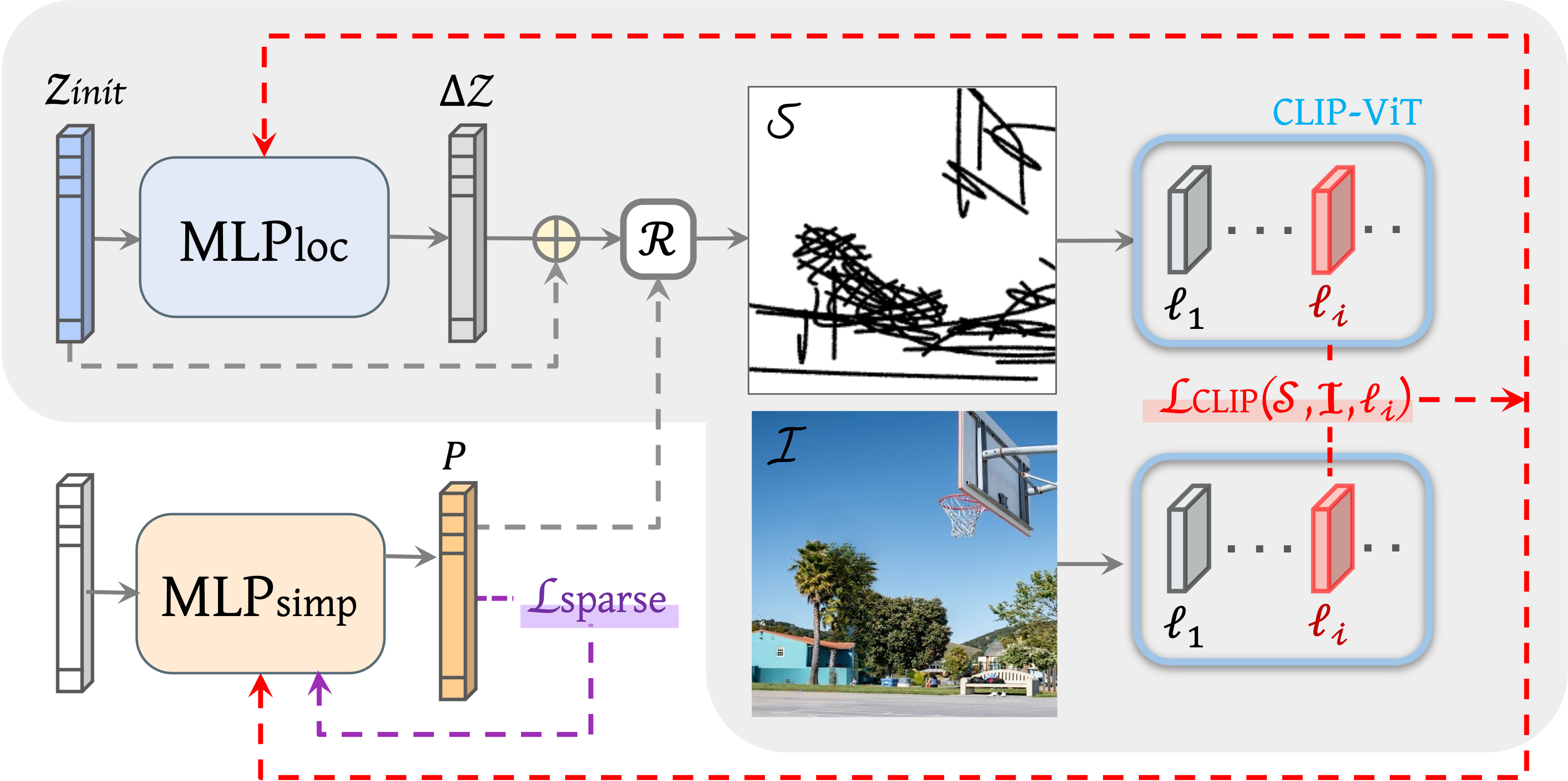
To realize the fidelity axis, we utilize different intermediate layers of CLIP-ViT to guide the training process, where shallow layers preserve the geometry of the image and deeper layers encourage the creation of looser sketches that rely more on the semantics of the scene. To realize the \emph{simplicity} axis, we jointly train an additional MLP network (MLP-simp) that learns how to best discard strokes without harming the meaning and recognizability of the sketch. The use of the networks over a direct optimization-based approach is crucial for achieving a learned simplification of the sketch.
Editing the Brush Style on SVGs